
-
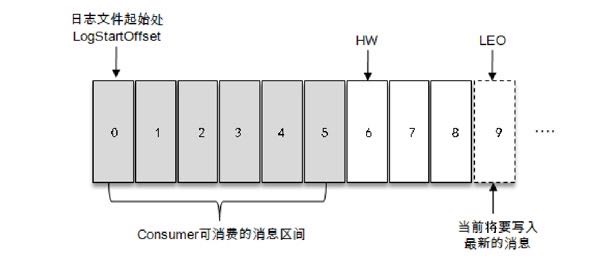
Kafka浅谈、什么是AR、OSR、ISR、HW和LEO以及之间的关系
kafka 多副本 Kafka 为分区引入了多副本(Replica)机制,通过增加副本数量可以提升容灾能力。同一分区的不同副本中保存的是相同的消息(当然在同一时刻,副本之间可能并非完全一样),副本之间是“一主多从”的关系,其中leader副本负责处理读写请求,follower副本只负责与leader副本的消息同步。副本处于不同的broker中,当leader副本出现故障时,从follower副本中…- 4.9k
- 0
-

精心整理的Hive数据导入导出的几种方式
作为数据仓库的Hive,存储着海量用户数据,在平常的Hive使用过程中,难免对遇到将外部数据导入到Hive或将Hive中的数据导出的情况。 Hive数据导入方式(Hive怎么导入数据) Hive数据导入方式主要有直接向表中插入数据、通过load加载数据、通过查询加载数据、查询语句中创建表并加载数据等四种。 直接向表中插入数据 语法格式 INSERT INTO TABLE tablename [PA…- 1.4k
- 0
-
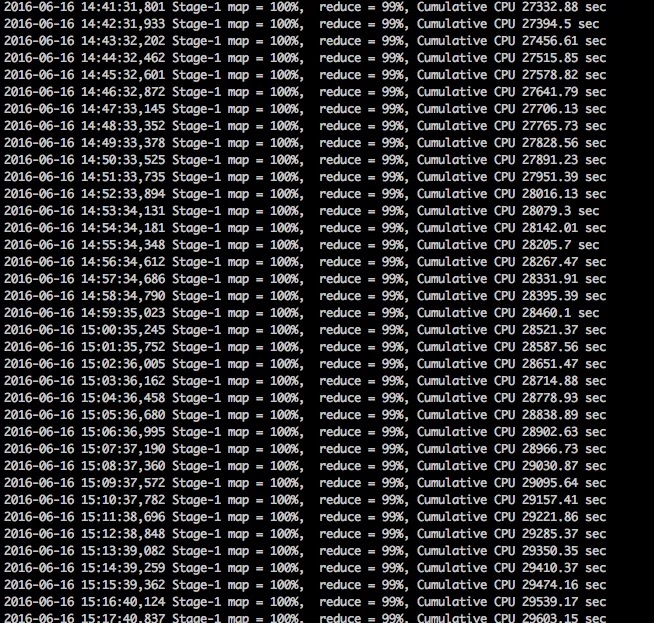
深入浅出Hive数据倾斜,最全面的讲解(好文收藏)
背景 我们日常使用HIVE SQL的时候可能会遇到这样一个令人苦恼的场景:执行一个非常简单的SQL语句,任务的进度条长时间卡在99%,不确定还需多久才能结束,这种现象称之为数据倾斜。这一现象出现的原因在于数据研发工程师主要关注分析逻辑和数据结果的正确性,却很少关注SQL语句的执行过程与效率。 本文将为你深入浅出地讲解什么是Hive数据倾斜、数据倾斜产生的原因以及面对数据倾斜的解决方法,从而帮你快速…- 1.9k
- 0
-

最全面的Hive开窗函数讲解和实战指南(必看)
窗口函数(Window Function)是 SQL2003 标准中定义的一项新特性,并在 SQL2011、SQL2016 中又加以完善,添加了若干拓展。 窗口函数不同于我们熟悉的常规函数及聚合函数,它为每行数据进行一次计算,特点是输入多行(一个窗口)、返回一个值。 在报表等数据分析场景中,你会发现窗口函数真的很强大,灵活运用窗口函数可以解决很多复杂问题,比如去重、排名、同比及环比、连续登录等等。…- 6.6k
- 0
-
hive 自定义函数浅谈(UDF、UDAF、UDTF)
hive为什么需要自定义函数 hive的内置函数满足不了所有的业务需求,hive提供很多的模块可以自定义功能,比如:自定义函数、serde、输入输出格式等。 常见自定义函数有哪些 UDF 用户自定义函数,user defined function。一对一的输入输出。(最常用的)。 UDTF 用户自定义表生成函数。user defined table-generate function.一对多的输入…- 1.7k
- 0
-
Hive的企业级调优
hive的企业级调优 Fetch抓取 Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。 select * from score;,在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。 在hive-default.xml.template文件中 hive.fetch.task.conversion默认是more,老版…- 279
- 0
-
Hive系统函数一览 (建议收藏)
Hive 提供了较完整的 SQL 功能,HQL 与 SQL 基本上一致,旨在让会 SQL 而不懂 MapReduce 编程的用户可以调取 Hadoop 中的数据,进行数据处理和分析。 这里记录了个人日常数据分析过程中 Hive SQL 需要的查询函数,方便手头随时查询,定期更新补充。 特殊说明:本文档整理内容为作者常用部分,不代表hive只有这些,感兴趣也可以查看Hive函数官方文档https:/…- 1.6k
- 0
-
讲一讲Hive的分区表与分桶表概念和使用场景, 顺便聊聊动态分区的实现
Hive将表划分为分区(partition)表和分桶(bucket)表。 分区表在加载数据的时候可以指定加载某一部分数据,并不是全量的数据,可以让数据的部分查询变得更快。分桶表通常是在原始数据中加入一些额外的结构,这些结构可以用于高效的查询,例如,基于ID的分桶可以使得用户的查询非常的块。 Hive分区表 Hive分区表的概念? Hive分区是将数据表的某一个字段或多个字段进行统一归类,而后存储在…- 2k
- 0
-
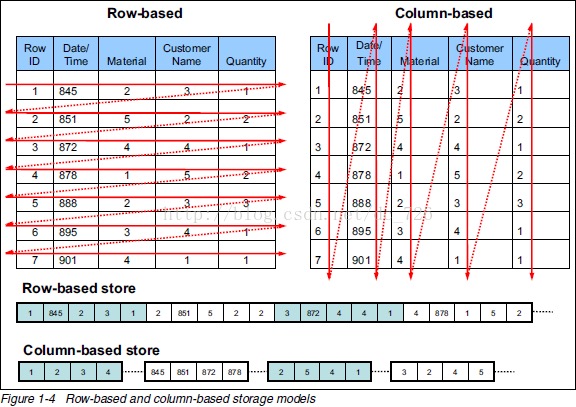
一文搞懂Hive存储格式及压缩格式,太清晰了!
Hive底层数据是以HDFS文件的形式存储在Hadoop中的,选择一个合适的文件存储格式及压缩方式,也是 Hive 优化的一个重点。不同的文件存储格式及压缩格式,同时代表着不同的数据存储组织方式,对于性能优化表现会有很大不同。 本文将会对Hive的存储格式、压缩格式等进行介绍和讲解,并依托案例从各个角度剖析对性能的优影响,也会讲述个人在实际工作中的一些选择和建议。 Hive 存储格式有哪些? Hi…- 5.1k
- 0
-

介绍一款Hive数仓可视化神器、Dbeaver的配置和使用方法
Dbeaver是一个图形化的界面工具,专门用于与各种数据库的集成,通过dbeaver我们可以与各种数据库进行集成。通过图形化界面的方式来操作我们的数据库与数据库表,类似于我们的sqlyog或者navicat。 下载Dbeaver 我们可以直接从github上面下载我们需要的对应的安装包即可dbeaver或官网dbeaver 国内百度云Dbeaver地址 链接: https://pan.baidu.…- 4.2k
- 0
-
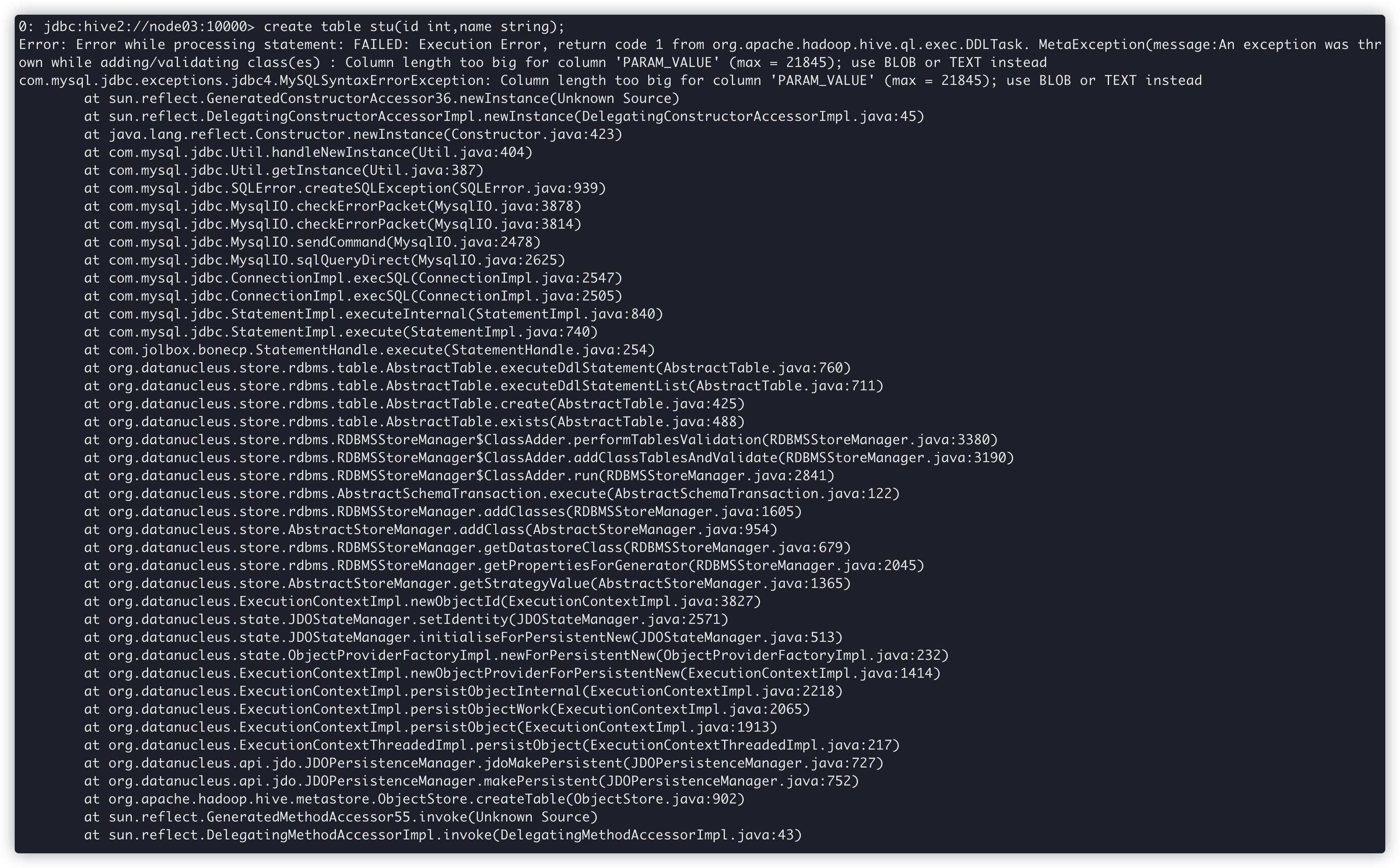
Hive 系列文章(五)hive 常见报错以及解决方案
整理汇总hive使用过程中遇到的问题以及解决办法。 问题一: Hive 创建表时报错 Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:An excepti…- 1.8k
- 0
-
hive 系列文章(四)HQL的基本语法
数据库相关的 DDL 1、创建库 CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] //关于数据块的描述 [LOCATION hdfs_path] //指定数据库在HDFS上的存储位置 [WITH DBPROPERTIES (property_…- 1k
- 0
-
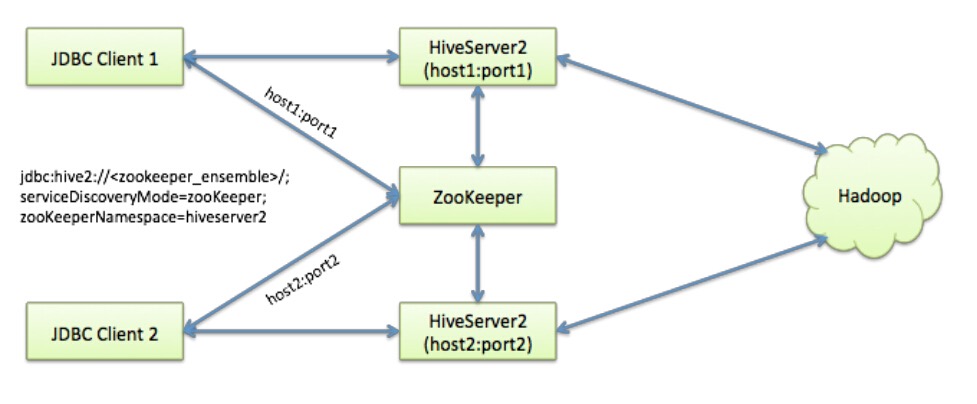
Hive 系列文章(三)Hive高可用部署 HiveServer2高可用及Metastore高可用
当部署的 Metastore 宕机或 HiveServer2 服务宕机时,两个服务可能持续相当长的时间不可用,直到服务被重新拉起。为了避免这种服务中断情况,在真实生产环境中需要部署Hive Metastore 高可用及HiveServer2的高可用。 那么怎样实现Hive高可用呢,下面分别从实现HiveServer2高可用和实现Metastore高可用两个方面讲解。 HiveServer2高可用 …- 1.6k
- 0
-
Hive 系列文章(二)安装及部署说明
Hive安装前置条件 按照 Hive 初始中所说,Hive 是基于 Hadoop 的数据仓库解决方案,所以默认代表已经安装 Hadoop。 常用解决方案为适应 MySQL 做为 Hive 的元数据库,所以先安装 MySQL。 启动 HDFS 和 YARN Hive的下载 下载链接http://mirror.bit.edu.cn/apache/hive/ 解压文件到指定安装目录 tar -zxvf …- 918
- 0
-
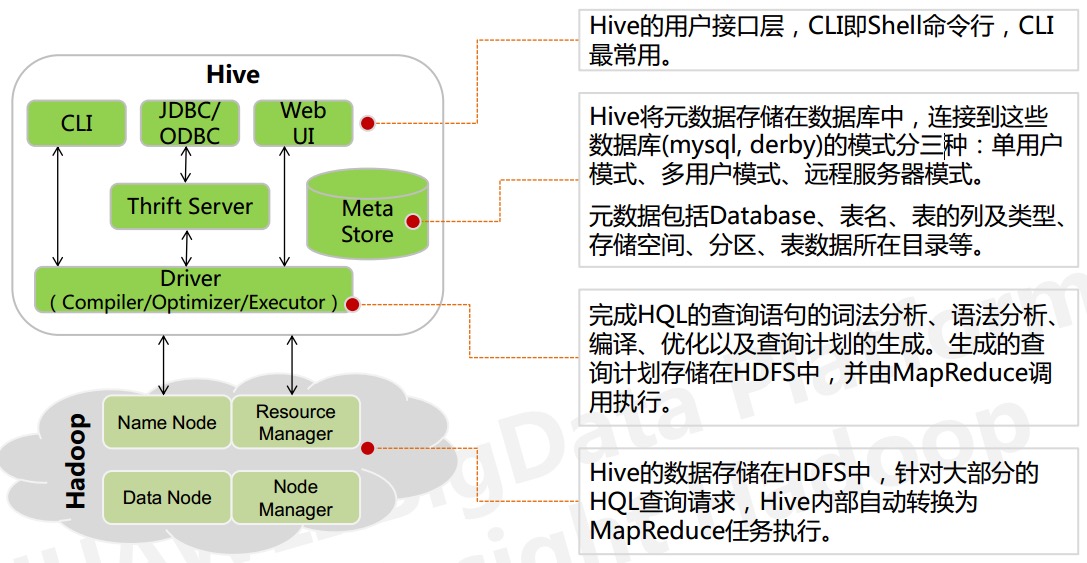
Hive 系列文章(一)初识hive
Hive 是什么? 官方解释: Hive 是基于 Hadoop 的数据仓库解决方案。由于 Hadoop 本身在数据存储和计算方面有很好的可扩展性和高容错性,因此使用 Hive 构建的数据仓库也秉承了这些特性。 简单而言: Hive 最初是由 Facebook 设计的,是基于 Hadoop 的一个数据仓库工具, 可以将结构化的数据文件映射为一张数据库表,并提供简单的类 SqL 查询语言(Hive S…- 695
- 0
-

超赞的kafka可视化客户端工具,让你嗨皮起来!
简介 Kafka Tool是一个用于管理和使用Apache Kafka®集群的GUI应用程序。 Kafka Tool提供了一个较为直观的UI可让用户快速查看Kafka集群中的对象以及存储在topic中的消息,提供了一些专门面向开发人员和管理员的功能,主要特性包括: 快速查看所有Kafka集群信息,包括其brokers, topics and consumers 查看分区中的消息内容并支持添加新消息…- 6.5k
- 0
-
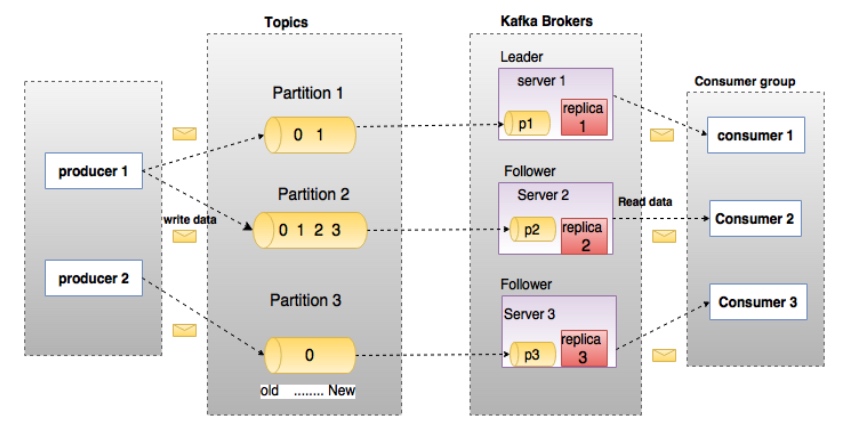
Kafka浅谈、kafka简介
什么是kafka? Kafka起初由Linkedin公司开发的一个多分区、多副本、多订阅者,基于zookeeper协调的分布式消息系统,常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。目前kafk已经定位于一个分布式流失处理平台。它以高吞吐、可持久化、可水平扩展、支持流数据处理等多种特性而被广泛使用。 kafka…- 387
- 0
-
kafka集群部署与安装
下载安装包(http://kafka.apache.org) kafka_2.11-1.1.0.tgz 规划安装目录 /opt/module 上传安装包到node01服务器,并解压 cd /opt/software tar -zxf kafka_2.11-1.1.0.tgz -C /opt/module/ 修改配置文件 在node01上修改 node01执行以下命令进行修改配置文件 # 进入到ka…- 193
- 0
-
2022 高效Flink学习路线经验分享(持续更新中)
学习 Flink 资源地址 官方文档 https://flink.apache.org/ gitHub源码地址 https://github.com/apache/flink Flink 中文社区视频课程 https://github.com/flink-china/flink-training-course (由 Apache Flink PMC 规划的 Flink 入门完整学习体系,内容分为基…- 2.1k
- 0
-

HBase常用shell操作
本内容整理了部分常用命令、以及实验案例。Hbase有大量命令,此处只列举出部分。更多使用案例和方法,list命令已经有很好的支持。 目录 进入Hbase shell 进入命令 ➜ hbase-1.2.4 bin/hbase shell help 帮助命令 hbase(main):001:0> help HBase Shell, version 1.2.4, r67592f3d06274390…- 349
- 0
-
HBase三节点分布式集群搭建
下载HBase的压缩包 http://archive.cloudera.com/cdh5/cdh/5/ 我们在这个网址下载我们使用的zk版本为hbase-1.2.0-cdh5.14.2.tar.gz 解压HBase node01执行解压命令,将HBase的压缩包解压到node01服务器的/opt/module/路径下去,然后准备进行安装。 cd /opt/software/ tar -zxvf h…- 553
- 0
-
浅谈Flink的checkPoint机制
checkPoint基本概念 为了保证state的容错性,Flink需要对state进程checkPoint。 Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator/task的状态来生成快照,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序…- 1.1k
- 0
-
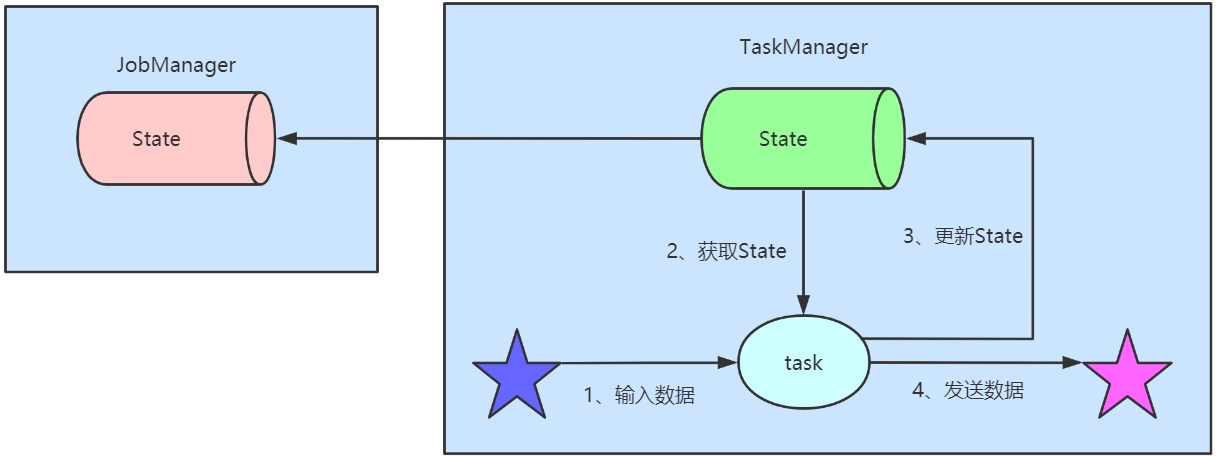
浅谈flink state状态管理机制
state 简述 Apache Flink® — Stateful Computations over Data Streams,flink是一个默认就有状态的分分析引擎,针对流失计算引擎中的数据往往是转瞬即逝,但在flink真实业务场景确不能这样,什么都不能留下,肯定是需要有数据留下的,针对这些数据留下来存储下来,在flink中叫做state,中文可以翻译成状态。 state 类型 Flink中…- 864
- 0
-
Flink如何自定义 mysql source与sink,实现mysql的读取和写入
数据库表准备 show databases; create database flink; use flink CREATE TABLE `user` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键id', `name` varchar(255) NOT NULL DEFAULT '' …- 3k
- 0

扫码打开当前页

扫码关注公众号
-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×