
-
Spark RDD持久化缓存机制
RDD 持久化 什么事RDD持久化缓存机制 RDD 持久化是 Spark 非常重要的特性之一。用户可显式将一个 RDD 持久化到内存或磁盘中,以便重用该RDD。RDD 持久化是一个分布式的过程,其内部的每个 Partition 各自缓存到所在的计算节点上。RDD 持久化存储能大大加快数据计算效率,尤其适合迭代式计算和交互式计算。 如何对rdd设置缓存 Spark 提供了 persist 和 cac…- 1.1k
- 0
-
Spark RDD的依赖关系以及DAG划分stage
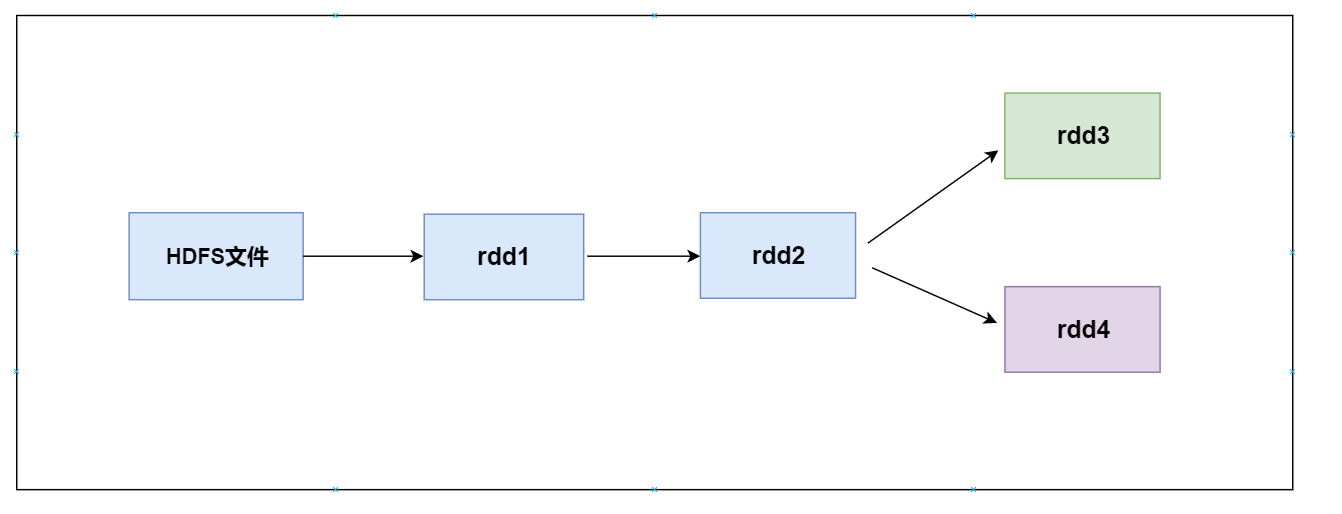
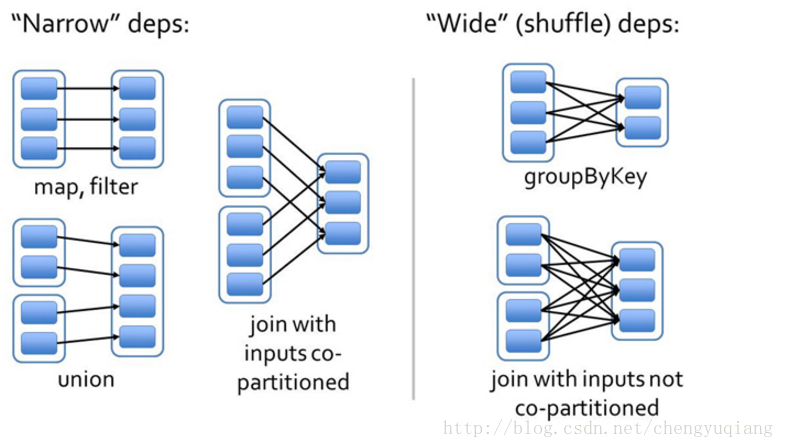
RDD 的宽依赖和窄依赖 由于 RDD 是粗粒度的操作数据集,每个 Transformation 操作都会生成一个新的 RDD,所以 RDD 之间就会形成类似流水线的前后依赖关系;RDD 和它依赖的父 RDD(s)的关系有两种不同的类型,即窄依赖(Narrow Dependency)和宽依赖(Wide Dependency)。 窄依赖 指的是子 RDD 只依赖于父 RDD 中一个固定数量的分区。 …- 1.1k
- 0
-

Spark的算子Transformation和Action
RDD的算子分类 transformation(转换) 根据已经存在的rdd转换生成一个新的rdd, 它是延迟加载,它不会立即执行 action (动作) 它会真正触发任务的运行,将rdd的计算的结果数据返回给Driver端,或者是保存结果数据到外部存储介质中 RDD transformation transformation API 是惰性的,调用这些API比不会触发实际的分布式数据计算,而仅仅…- 1.4k
- 0
-
Spark集群安装部署
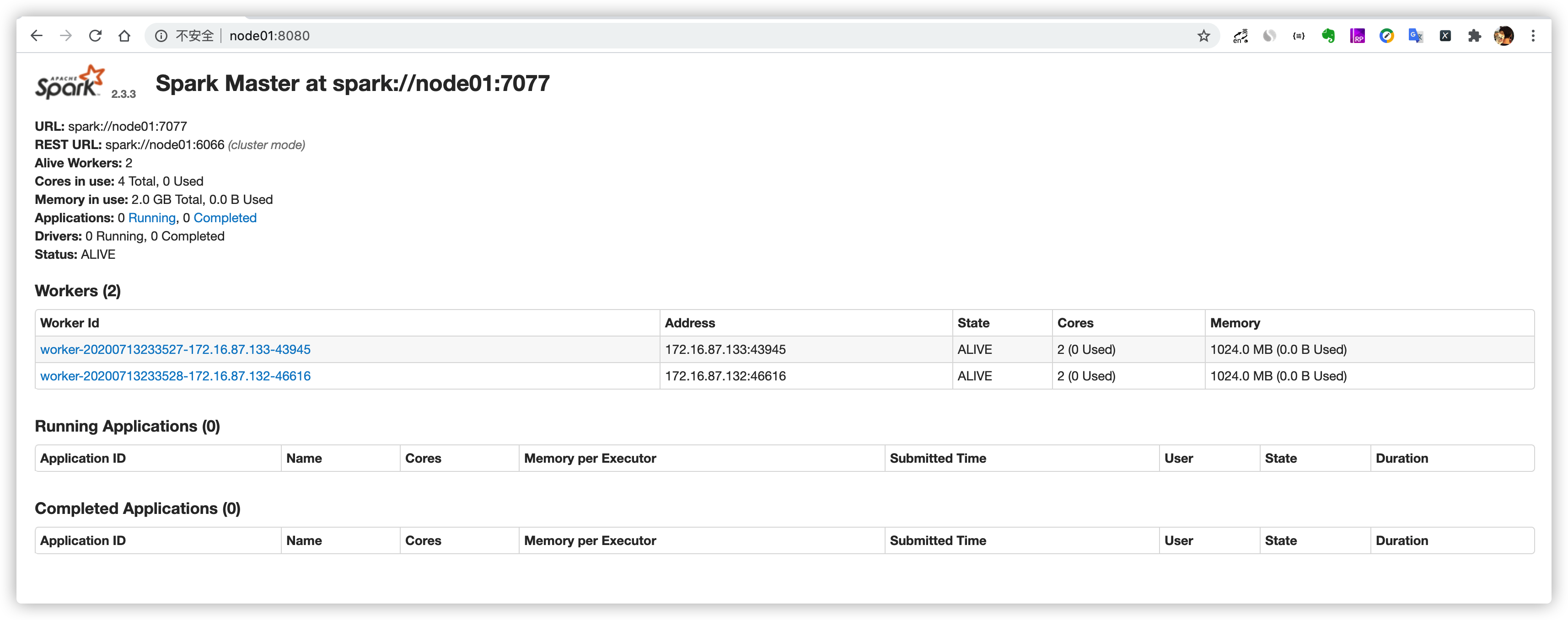
安装基础 Java8安装成功 zookeeper安装成功 下载安装包 spark官网下载链接 作者百度网盘链接: https://pan.baidu.com/s/1ytjRn231Gx3RFDSncrj5qQ 密码: 77tm 上传安装包到服务器 cd /opt/software/ [hadoop@node01 software]$ ls 3.51.0.tar.gz clickhouse-serv…- 624
- 0
-
SSpark伪分布式安装
下载 Spark 安装包 官网下载 http://spark.apache.org/downloads.html 安装前准备 Java8 已安装 hadoop2.7.5 已安装 修改 Hadoop 配置文件 修改 Hadoop yarn-site.xml配置 vim ~/App/hadoop-2.7.3/etc/hadoop/yarn-site.xml <property> <n…- 203
- 0
-
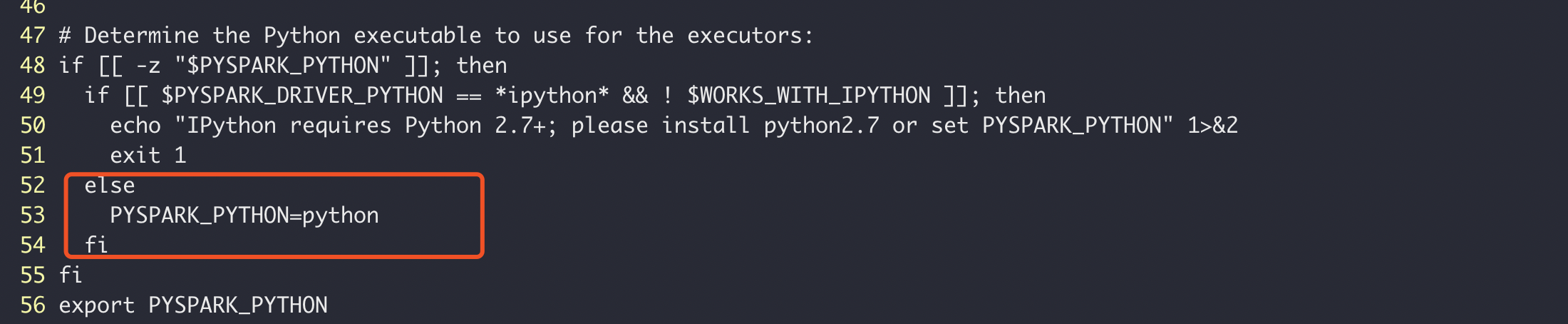
pyspark 如何设置python的版本
PySpark 在工作程序中都需要使用的为默认环境的python版本,怎样把python的版本切换成3的版本,您可以通过 PYSPARK_PYTHON 指定要使用的Python版本。 python3 环境需要提前安装好,如果没按照可以参考centos7 下python2与python3共存 修改spark-env.sh文件, 在末尾添加export PYSPARK_PYTHON=/usr/bin/…- 999
- 0


扫码打开当前页

扫码关注公众号
-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×