
-
Spark RDD持久化缓存机制
RDD 持久化 什么事RDD持久化缓存机制 RDD 持久化是 Spark 非常重要的特性之一。用户可显式将一个 RDD 持久化到内存或磁盘中,以便重用该RDD。RDD 持久化是一个分布式的过程,其内部的每个 Partition 各自缓存到所在的计算节点上。RDD 持久化存储能大大加快数据计算效率,尤其适合迭代式计算和交互式计算。 如何对rdd设置缓存 Spark 提供了 persist 和 cac…- 1.1k
- 0
-
Spark RDD的依赖关系以及DAG划分stage
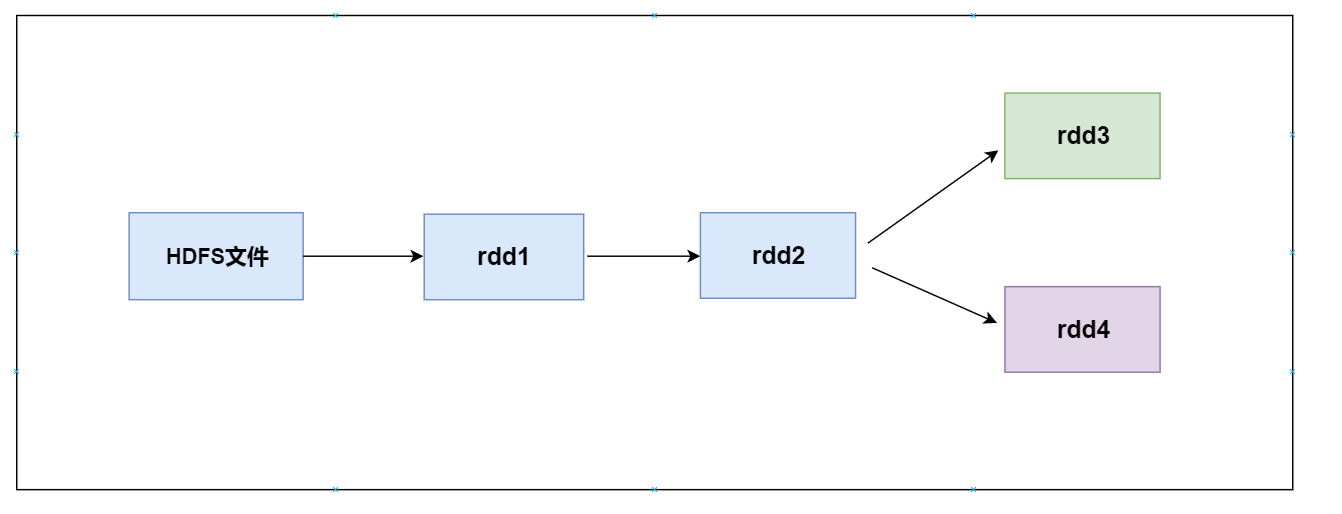
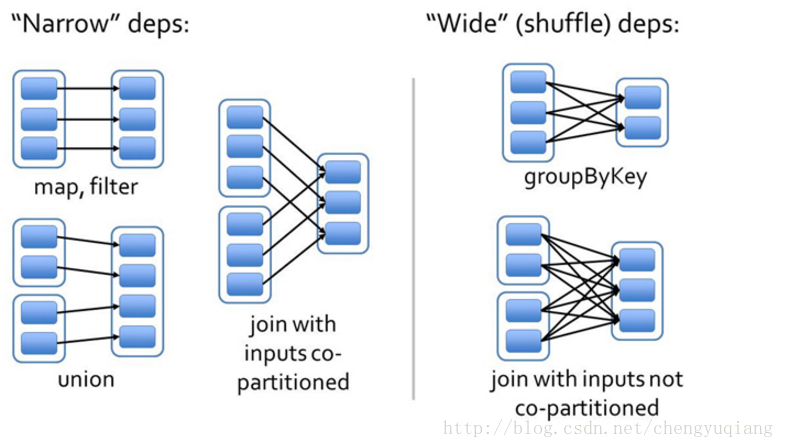
RDD 的宽依赖和窄依赖 由于 RDD 是粗粒度的操作数据集,每个 Transformation 操作都会生成一个新的 RDD,所以 RDD 之间就会形成类似流水线的前后依赖关系;RDD 和它依赖的父 RDD(s)的关系有两种不同的类型,即窄依赖(Narrow Dependency)和宽依赖(Wide Dependency)。 窄依赖 指的是子 RDD 只依赖于父 RDD 中一个固定数量的分区。 …- 1.1k
- 0
-

Spark的算子Transformation和Action
RDD的算子分类 transformation(转换) 根据已经存在的rdd转换生成一个新的rdd, 它是延迟加载,它不会立即执行 action (动作) 它会真正触发任务的运行,将rdd的计算的结果数据返回给Driver端,或者是保存结果数据到外部存储介质中 RDD transformation transformation API 是惰性的,调用这些API比不会触发实际的分布式数据计算,而仅仅…- 1.4k
- 0
-
Spark集群安装部署
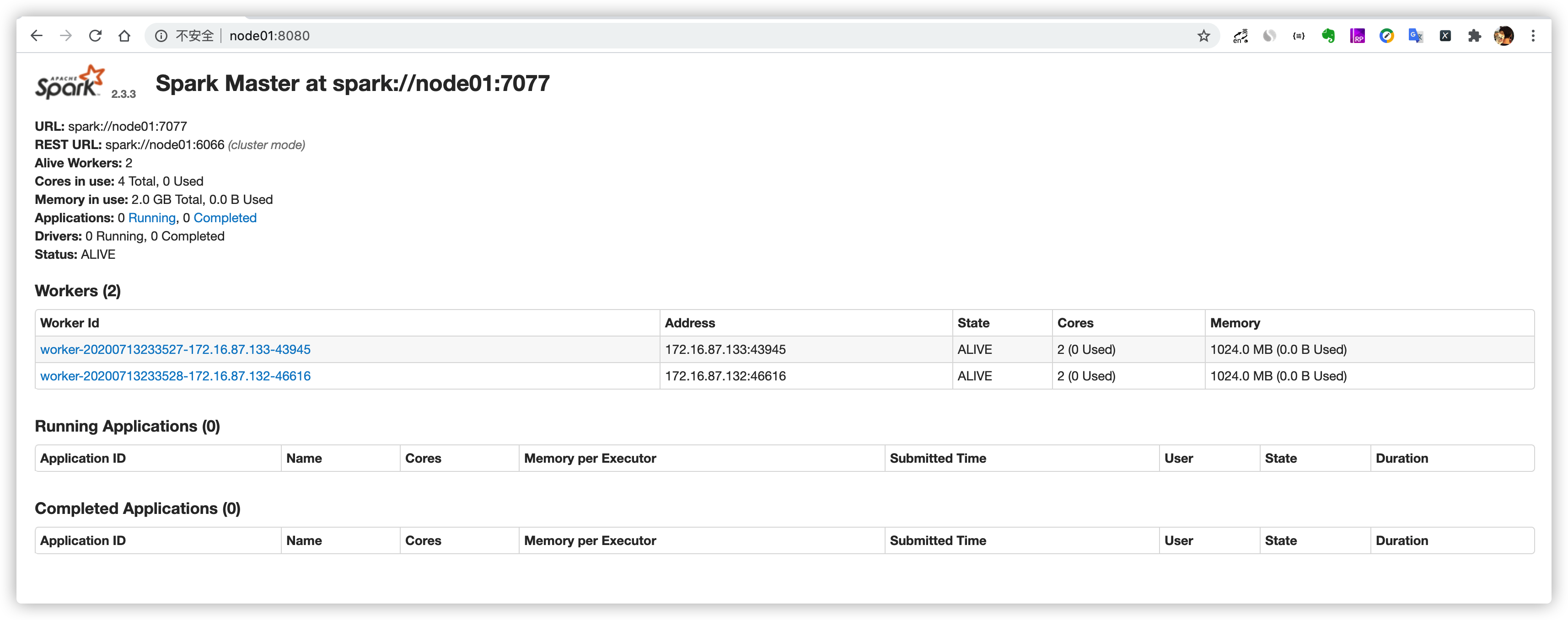
安装基础 Java8安装成功 zookeeper安装成功 下载安装包 spark官网下载链接 作者百度网盘链接: https://pan.baidu.com/s/1ytjRn231Gx3RFDSncrj5qQ 密码: 77tm 上传安装包到服务器 cd /opt/software/ [hadoop@node01 software]$ ls 3.51.0.tar.gz clickhouse-serv…- 624
- 0
-
SSpark伪分布式安装
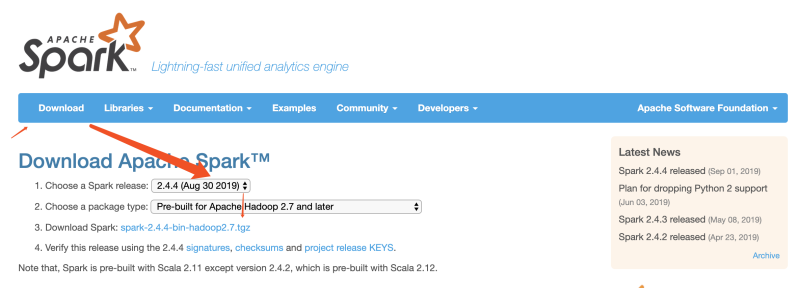
下载 Spark 安装包 官网下载 http://spark.apache.org/downloads.html 安装前准备 Java8 已安装 hadoop2.7.5 已安装 修改 Hadoop 配置文件 修改 Hadoop yarn-site.xml配置 vim ~/App/hadoop-2.7.3/etc/hadoop/yarn-site.xml <property> <n…- 203
- 0
-
scala语言学习(十一)、scala隐式转换和隐式参数
scala提供的隐式转换和隐式参数功能,是非常有特色的功能。是Java等编程语言所没有的功能。它可以允许你手动指定,将某种类型的对象转换成其他类型的对象或者是给一个类增加方法。通过这些功能,可以实现非常强大、特殊的功能。 隐式转换其核心就是定义一个使用 implicit 关键字修饰的方法实现把一个原始类转换成目标类,进而可以调用目标类中的方法 隐式参数 所谓的隐式参数,指的是在函数或者方法中,定义…- 188
- 0
-
scala语言学习(十)、scala泛型、scala上下界
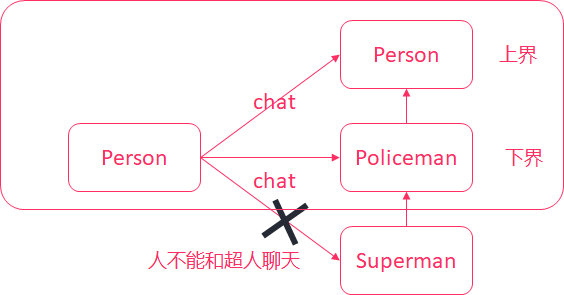
泛型 scala和Java一样,类和特质、方法都可以支持泛型。我们在学习集合的时候,一般都会涉及到泛型。在scala中,使用方括号来定义类型参数。 scala> val list1:List[String] = List("1", "2", "3") list1: List[String] = List(1, 2, 3) 定义一个泛…- 248
- 0
-
scala语言学习(九)、scala提取器(Extractor)
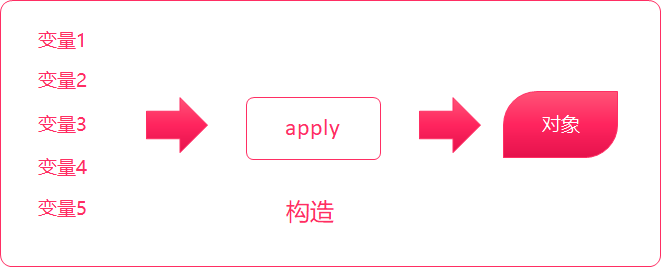
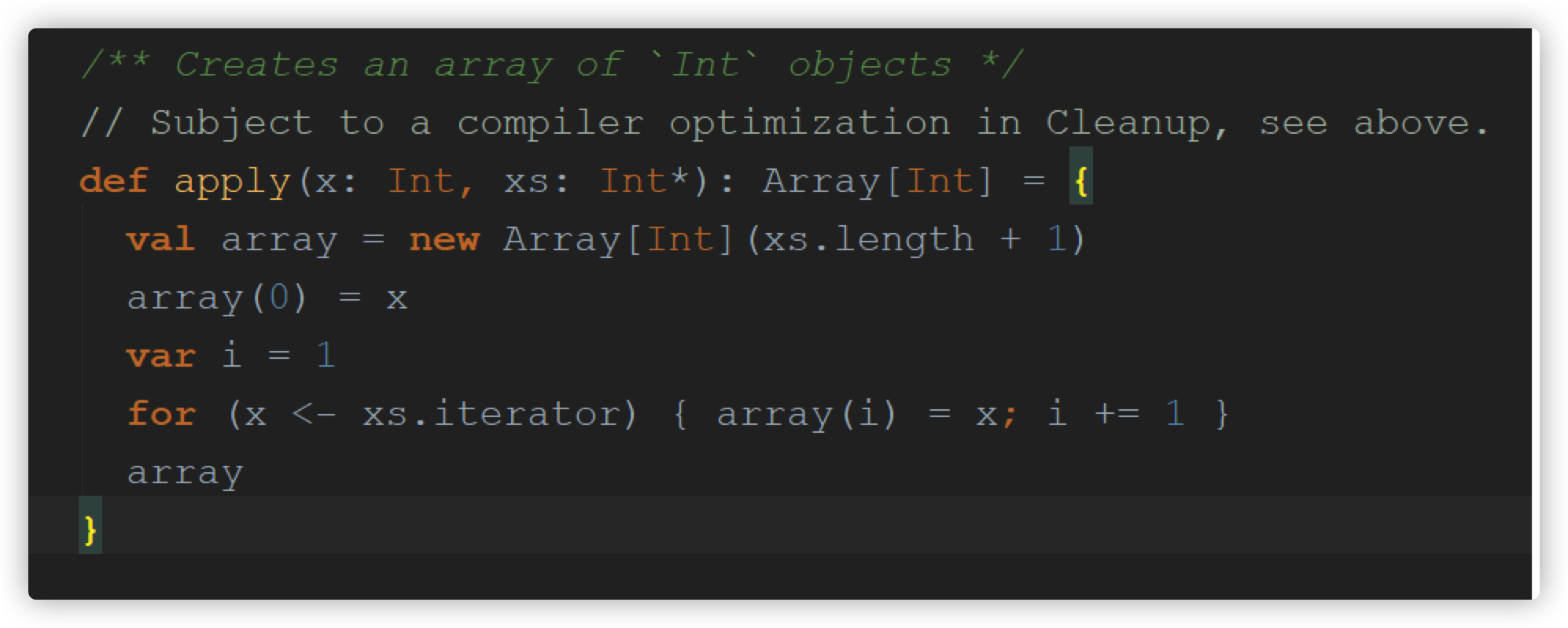
提取器(Extractor) 提取器是从传递给它的对象中提取出构造该对象的参数。(回想样例类进行模式匹配提取参数) scala 提取器是一个带有unapply方法的对象,unapply方法算是apply方法的反向操作,unapply接受一个对象,然后从对象中提取值,提取的值通常是用来构造该对象的值。 class Student { var name:String = _ // 姓名 var age…- 161
- 0
-
scala语言学习(八)、scala异常处理机制
异常处理 Scala 的异常处理和其它语言比如 Java 类似,Scala 的方法可以通过抛出异常的方法的方式来终止相关代码的运行,而不必通过返回值。 异常场景 package xin.studytime.App object ExceptionDemo01 { def main(args: Array[String]): Unit = { val i = 10 / 0 println("…- 710
- 0
-

scala语言学习(七)、scala模式匹配和以及scala样例类
scala有一个十分强大的模式匹配机制,可以应用到很多场合。而且scala还提供了样例类,对模式匹配进行了优化,可以快速进行匹配。 switch语句 类型查询 以及快速获取数据 模式匹配 匹配字符串 package xin.studytime.App import scala.util.Random object CaseDemo01 extends App { val arr = Array(&…- 165
- 0
-
scala语言学习(六)、scala面向对象编程类、对象、继承、trait特质
scala面向对象编程之类 类的定义 scala是支持面向对象的,也有类和对象的概念。定义一个Customer类,并添加成员变量/成员方法。添加一个main方法,并创建Customer类的对象,并给对象赋值,打印对象中的成员,调用成员方法 class Customer { var name:String = _ var sex:String = _ val registerDate:Date = …- 261
- 0
-

scala语言学习(五)、scala柯里化以及应用
概念 柯里化(currying, 以逻辑学家Haskell Brooks Curry的名字命名)指的是将原来接受两个参数的函数变成新的接受一个参数的函数的过程。新的函数返回一个以原有第二个参数作为参数的函数。 在Scala中方法和函数有细微的差别,通常编译器会自动完成方法到函数的转换。 Scala中柯里化的形式 Scala中柯里化方法的定义形式和普通方法类似,区别在于柯里化方法拥有多组参数列表,每…- 210
- 0
-
scala语言学习(四)、scala函数式编程
函数式编程 我们将来使用Spark/Flink的大量业务代码都会使用到函数式编程。 下面的这些操作是学习的重点,先来感受下如何进行函数式编程以及它的强大 遍历 - foreach 方法描述 foreach(f: (A) ⇒ Unit): Unit 方法说明 foreach API 说明 参数 f: (A) ⇒ Unit 接收一个函数对象作为参数函数的输入参数为集合的元素返回值为空 返回值 Unit…- 209
- 0
-
scala语言学习(三)、scala的数组、Map、元组、集合
数组 scala中数组的概念是和Java类似,可以用数组来存放同类型的一组数据。 数组类型分为定长数组和变长数组两种。 定长数组 定长数组指的是数组的长度是不允许改变的,但数组的元素是可以改变的。 语法 // 通过指定长度定义数组 val/var 变量名 = new Array[元素类型](数组长度) // 用元素直接初始化数组 val/var 变量名 = Array(元素1, 元素2, 元素3.…- 160
- 0
-
scala语言学习(二)、scala的基本使用
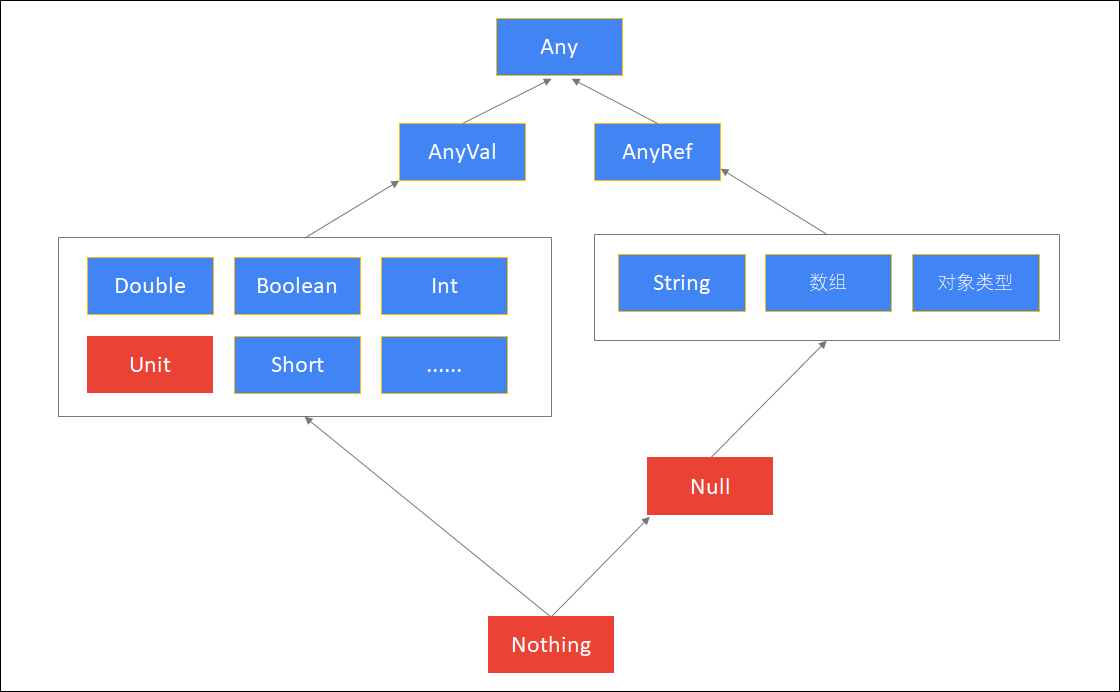
变量声明 语法格式 val/var 变量名称:变量类型 = 初始值 val定义的是不可重新赋值的变量(值不可修改) var定义的是可重新赋值的变量(值可以修改) scala中声明变量是变量名称在前,变量类型在后,跟java是正好相反 scala的语句最后不需要添加分号 演示 #使用val声明变量,相当于java中的final修饰,不能在指向其他的数据了 val a:Int = 10 #使用var声…- 304
- 0
-
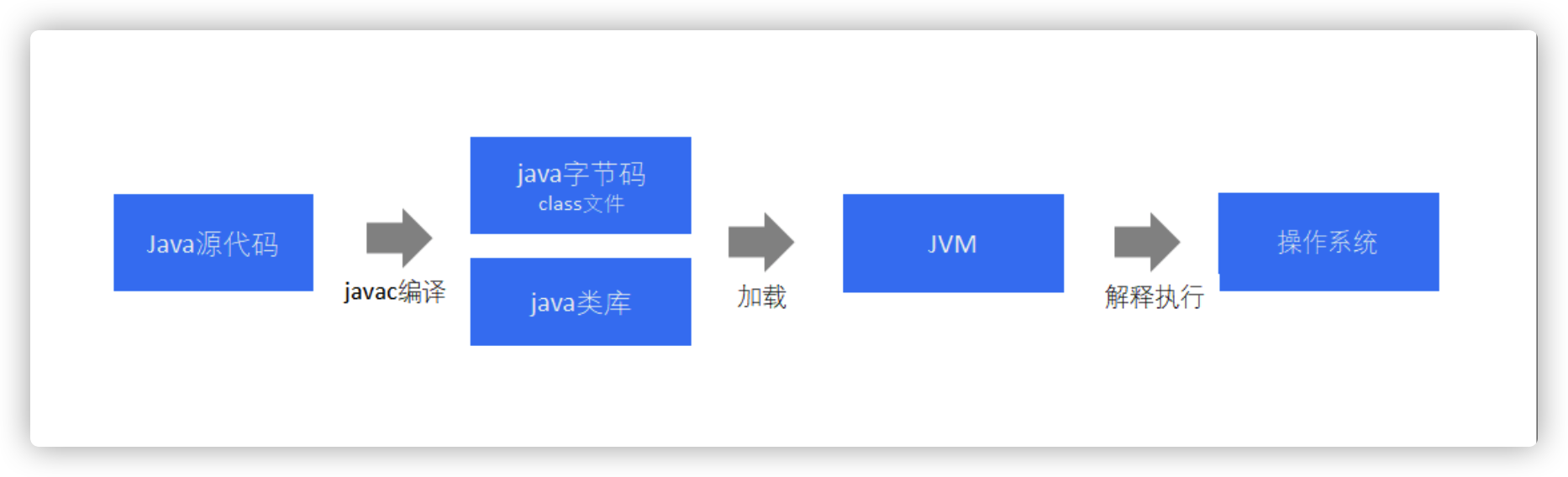
scala语言学习(一)、scala介绍
scala简介 scala是运行在 JVM 上的多范式编程语言,同时支持面向对象和面向函数编程。早期scala刚出现的时候,并没有怎么引起重视,随着Spark和Kafka这样基于scala的大数据框架的兴起,scala逐步进入大数据开发者的眼帘。scala的主要优势是它的表达性。 官网地址 http://www.scala-lang.org 为什么要使用scala 开发大数据应用程序(Spark程…- 317
- 0
-
hadoop集群配置LZO压缩以及支持Hive
下载以及编译lzo源码包 LZO源码包地址 将下载的源码包使用maven进行编译 使用 mvn clean package,编译之后将生成adoop-lzo-0.4.20.jar的jar包 特殊说明:也可以不进行编译,直接使用作者编译好的lzo jar包。链接: https://pan.baidu.com/s/13IjKDEokh_dqkGoDY1bIFA 密码: fbtf 将编译之后的jar包上…- 574
- 0
-
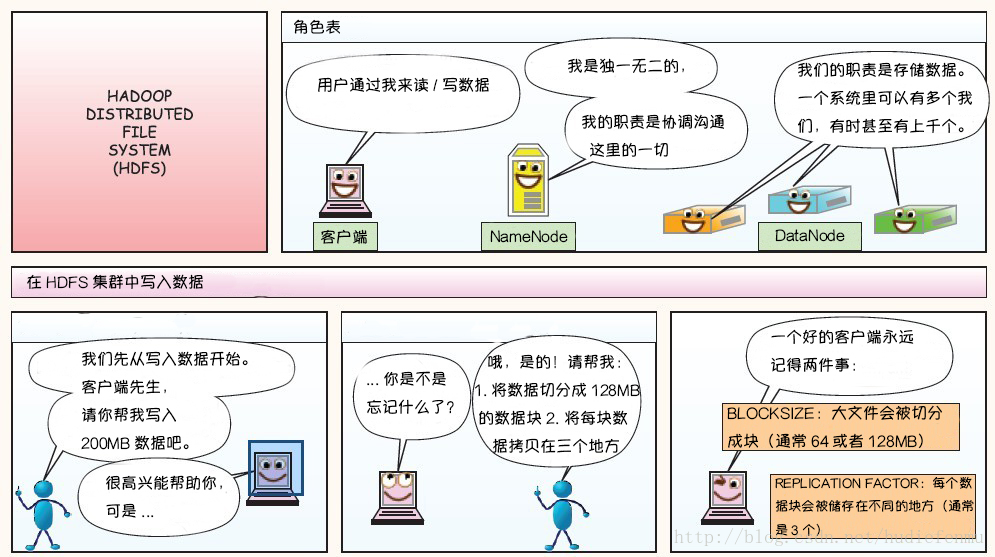
图解HDFS存储原理
HDFS是现在最受欢迎和被人们说熟知的分布式文件系统。本文翻译了经典的 HDFS 原理讲解漫画,以一种通俗易懂的方式帮助 HDFS 初学者理解HDFS 的原理。 HDFS写数据原理 HDFS读数据原理 HDFS故障类型和其检测方法 读写故障的处理 DataNode 故障处理 副本布局策略- 887
- 0
-
HDFS的shell常用命令操作
HDFS的命令有两种风格: hadoop fs开头 hdfs dfs开头 两种命令都可以使用,效果相同,建议使用hdfs dfs,因为hadoop fs为老版本用法,兼容保留。 启动集群 start-dfs.sh start-yarn.sh 帮助命令 [hadoop@node01 ~]$ hdfs dfs -help ls 查看HDFS系统根目录 [hadoop@node01 ~]$ hdfs d…- 723
- 0
-
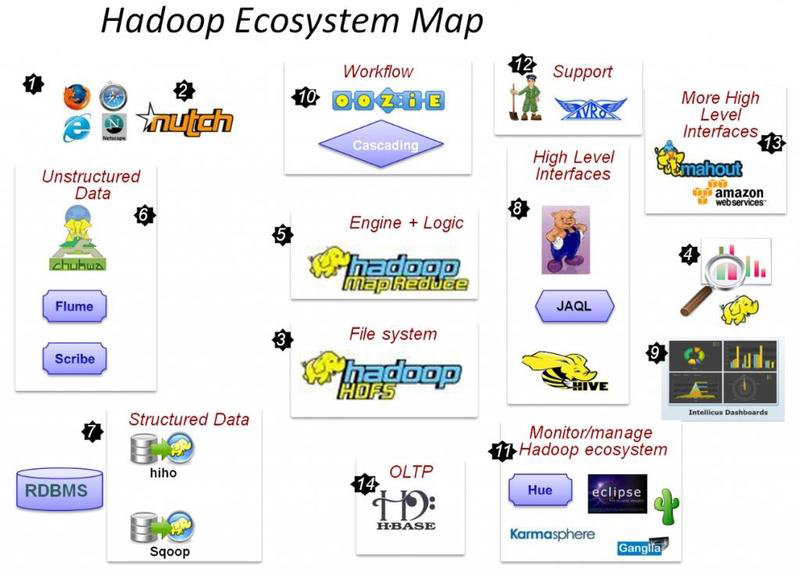
Hadoop 发展背景和简介
Hadoop产生的背景 HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。 基于google开源三驾马车中的GFS的开源实现 2003年google发表GFS论文 2004年hdfs开源 2004年“谷歌MapReduce”论文 2005年Nu…- 535
- 0
-
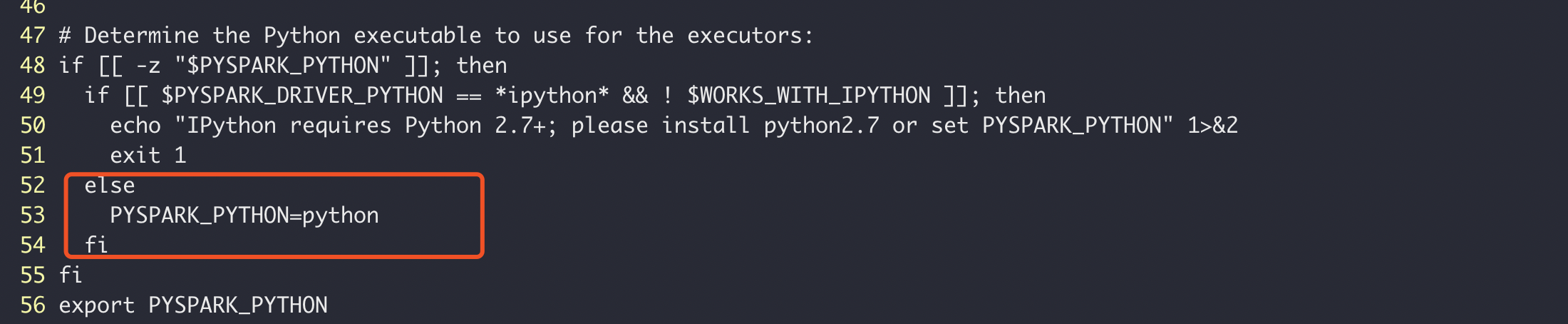
pyspark 如何设置python的版本
PySpark 在工作程序中都需要使用的为默认环境的python版本,怎样把python的版本切换成3的版本,您可以通过 PYSPARK_PYTHON 指定要使用的Python版本。 python3 环境需要提前安装好,如果没按照可以参考centos7 下python2与python3共存 修改spark-env.sh文件, 在末尾添加export PYSPARK_PYTHON=/usr/bin/…- 999
- 0


扫码打开当前页

扫码关注公众号
-
¥优惠劵使用时效:无法使用使用时效:
之前
使用时效:永久有效优惠劵ID:×